
Under det senaste året har vi arbetat en hel del med baksidan av Booli. Ett projekt som vi jobbat med är att flytta sökningarna på bostäder till salu och slutpriser från MySQL till en ny sökmotor som heter Elasticsearch.
Visste du att Booli hade sin början som ett PHP-projekt med MySQL som databas bakom, den så kallade LAMP-stacken? Det var en väldigt populär stack år 2007 när Booli startade.
Under åren som gått har vi flyttat ut en hel del funktionalitet ur det ursprungliga PHP-baserade Booli-systemet och byggt till många nya saker bredvid, så Booli idag är ganska annorlunda med många olika tjänster som pratar med varandra. Men en liten kärna av den ursprungliga koden finns fortfarande kvar. En del av det är det API som bland annat driver sökningarna på bostäder till salu och slutpriser som görs på booli.se. För att göra dem snabba så har vi använt oss av specialanpassade tabeller i MySQL med index uppsatta för de kolumner som man kunnat filtrera och sortera på.
Det har generellt funkat bra under alla åren, men har haft några nackdelar:
- Svårt att skala allt eftersom vår trafik växer. Det har alltid gått att köpa en ny, snabbare databas-server för att hantera den tillväxt vi haft, men det är sånt som tar tid.
- Krångligt att anpassa vilka fält som är sökbara och tillgängliga i vårt API. Ny funktionalitet har krävt ändringar i tabellstrukturen i SQL och eftersom tabellerna är väldigt stora har det varit svårt att göra utan att påverka användarnas upplevelse.
Flytten till Elasticsearch
Vi valde därför att röra oss bort från MySQL som sökmotor och valde istället Elasticsearch, en distribuerad dokument-databas fokuserad på just sök. Det vi nu har landat i är en arkitektur där vår primära data fortfarande ligger lagrad i MySQL men synkas över till Elasticsearch när ändringar kommer in.
Eftersom det var så många olika funktioner som sökte på datan på olika sätt var det inte helt lätt att byta ut allt, särskilt som det var i gamla delar av vår kodbas. Jag vet inte hur många gånger vi hittade någon ny spännande funktion som ingen kände till längre som också behövde anpassas. 😄 Det ledde oss också in på lite av en omväg där vi även lade om driften av API:et och flyttade in det i Kubernetes som vi använder för att drifta de flesta av våra system. Genom att ta det ett steg i taget och gradvis växla över till det nya så har vi nu lyckats arbeta bort allt gammalt och är nu helt MySQL-fria i sökningarna sedan ett par veckor tillbaka.
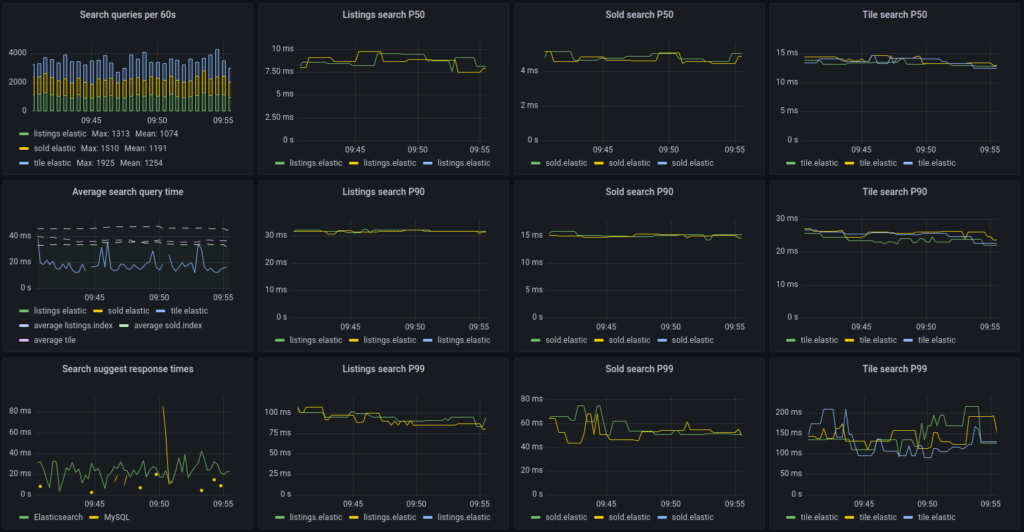
Lite vinster vi ser redan nu
- Enklare att skala, vi kan öka på antalet noder i Elasticsearch efter den last vi ser.
- Enkelt att göra vad som helst sökbart. Elasticsearch bygger själv index för alla fält och behöver något anpassas kan vi bara göra en ändring och vänta på att all data synkas över igen utan någon nedtid.
- Lika snabbt för det mesta (även MySQL var väldigt snabbt så som vi använde det) och bättre prestanda i en del konstiga specialfall. T.ex. om man sökte på alla slutpriser i Sverige och sorterade på något konstigt så spårade MySQL ur lite medan Elasticsearch beter sig stabilt.
- Bättre stöd för andra sätta att söka på, som t.ex fritextsök och sökning via geografiska polygoner.
En nackdel med det är så klart att det är ytterligare en pusselbit till som ska driftas, uppdateras och övervakas. Men hittills har det fungerat bra och vi är nöjda.
Allt sammantaget så har vi nu bättre möjligheter än någonsin att vidareutveckla sökupplevelsen i våra produkter, vilket ju är kärnan i det vi gör.
Utmaningar med distribuerade system
Ett problem vi stött på, som vi delvis hade tidigare också, är hur vi håller data i synk mellan systemen och hur vi kan veta att en ändring gått ut till alla system. Ett exempel på det är när en mäklare rapporterar in ett slutpris som inloggad på Hittamäklare så har vi svårare att veta när det slagit igenom i alla system och mäklaren själv kan se att det sparats.
Men vi har relativt få sådana problem eftersom den mesta av vår data inte kommer från användarna själva utan hämtas in utifrån, så hittills har det varit hanterbart. Men bygger man en produkt där användare mycket oftare behöver se sin egen data uppdaterad direkt så är det inte säkert att det är rätt väg att gå.
Vill du hjälpa oss att göra mer sånt här? Kul! Läs mer om hur det är att jobba hos oss och se vad vi letar efter.